ML-Augmented Automation for Recovering Links between Pull-Requests and Issues on GitHub
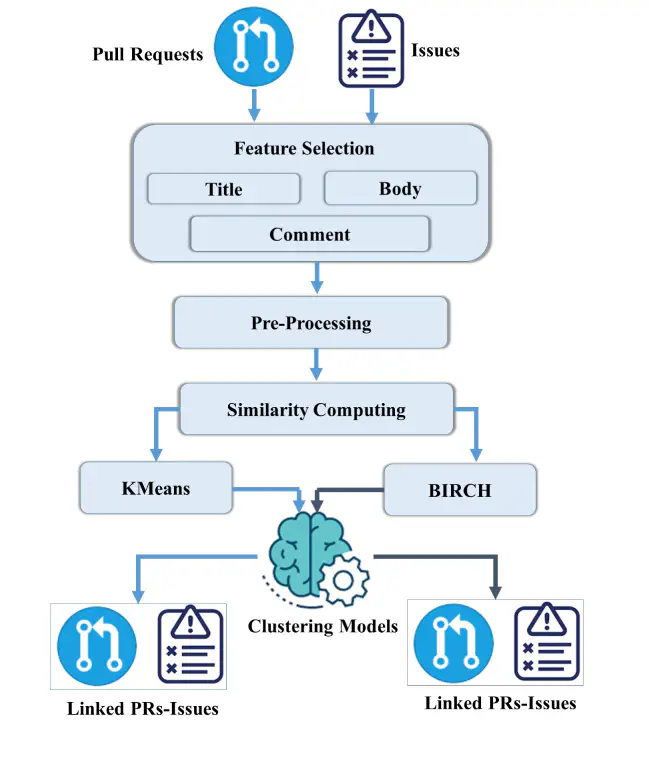 Image credit: Unsplash
Image credit: UnsplashAbstract
GitHub provides a distributed and collaborative platform to develop and maintain open-source projects. This social coding platform achieves this collaborative development, with or without coordination, using pull requests and issues artefacts. When the number of daily submitted issues rapidly grows up, especially in popular repositories, managing issues becomes more complicated. To help the repository’s developers in issues processing, there are external contributors who fix issues by submitting pull-requests. On GitHub, a pull-request is frequently linked with a submitted issue to show that a solution is in progress. Unfortunately, contributors might forget or be lazy to link the Pull-Requests with their corresponding Issues. Only a tiny share of these links are established, but a large portion of links are missed in the development history. However, manually recovering the links between Pull-Request and Issues from evolutionary development history is a challenging, time-consuming, and error-prone task, even for senior developers. In this article, we propose to build ML models to recover links between pull-requests and issues using two Machine Learning algorithms (KMeans and BIRCH) based on lexical and semantic weighting measurements. These models are evaluated using PI-Link ground-truth dataset. The obtained results show that pull-request and issue links can be recovered with an accuracy of 91.5% using BIRCH clustering algorithm.
Zakarea Alshara
Associate Professor of Software Engineering
My research interests include Software Engineering, Software Security, AI, and Cloud Computing.